
Trying to show up in AI answers right now feels like taking shots in the dark.
There’s no playbook from the LLMs, SEO alone isn’t getting brands into those responses anymore, and search has moved into a place where the old signals just don’t carry the same weight. The models powering these AI-search results look at content differently than the algorithms we spent years optimizing for.
But after a lot of testing, on our own sites and across client work, we’ve been able to pick up on the cues these systems consistently respond to. And once you understand those patterns, you can actually shape your content in ways that help you get included, trusted, and cited inside AI-generated answers.
TL:DR
- GEO ≠ traditional SEO: Instead of chasing keywords and links alone, you’re optimizing entities, facts, and trust signals so LLMs (ChatGPT, Perplexity, Gemini, Claude, etc.) cite you in answers.
- Entity clarity is non-negotiable: Standardize brand/product names, link profiles via schema (sameAs), and aim for Knowledge Graph/Wikidata visibility.
- Structure content for machines: Use clear headings, lists, tables, and schema types (Organization, SoftwareApplication, FAQPage, HowTo) so models can easily lift snippets.
- Answer like a conversation: Lead with the direct answer (BLUF), then expand with nuance in natural, conversational language.
- Leverage UGC + digital PR: Mentions in Reddit, G2, TechCrunch, or podcasts reinforce authority. LLMs value consistent brand references, not just backlinks.
- Try LLMS.txt: Guide AI crawlers toward your most citable, evergreen resources (and avoid blocking too much).
- Make claims fact-checkable: Back every stat with a trusted external source (e.g., Gartner, Forrester, government data) in short, declarative statements.
- Publish original data: Surveys, product usage insights, or benchmarks turn you into the source LLMs cite, not just another reference.
- Keep content fresh: 95% of ChatGPT citations are <10 months old. Add “last updated” schema + quarterly refreshes to high-intent pages.
- Show real authorship (E-E-A-T): Add expert bylines, bios, and LinkedIn/GitHub links. LLMs (and humans) trust content tied to real people.
- Build deep topic clusters: Cover core themes comprehensively (definitions, how-tos, case studies, comparisons). Include low-volume but high-context topics to strengthen authority.
- Stick to plain HTML: Pricing, features, and key facts must be crawlable in HTML (not hidden in JS or images) or LLMs won’t “see” them.
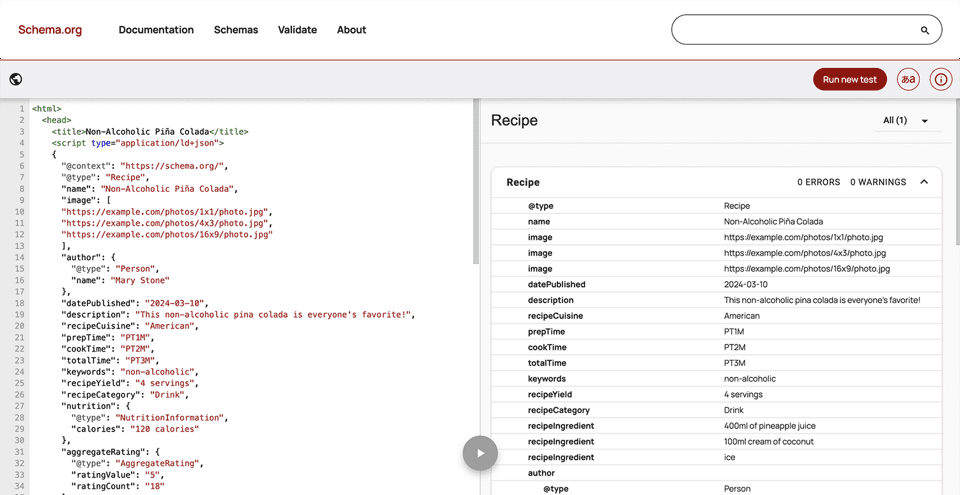
Strategy 1: Use Structured Formatting, Clear Headings + Schema
It’s a classic SEO tactic that carries straight into GEO; structured formatting, clear headings, and schema, etc, because we’re trying to optimize for machines, and machines need clarity to quickly understand and reuse your content.
So if your page is a wall of text, the model struggles to isolate answers.

Then there’s Schema. It acts as a label for content, explicitly telling machines: this is an FAQ, this is a Product description, this is an Article.
For SaaS specifically, schema types like Organization, SoftwareApplication, FAQPage, and HowTo are high-value because they map your brand, product, and support content into formats machines already expect. And when you fill out properties like pricing, version, operating system, and reviews, it makes your data even more complete.
Here’s where all this effort shows up:
- Perplexity often displays FAQs and tabular data because it can easily parse structured formats.
- Google’s AI Overviews lean heavily on schema to decide what’s authoritative and what’s just noise.
- Even ChatGPT, when pulling from retrieval plugins, tends to favor passages that are wrapped in headings or bullet lists because it’s easier for it to lift a self-contained snippet.
Here’s how to improve your content structure and schema:
- Add clear headings: every major idea should have its own H2 or H3 so models can identify sections easily.
- Break up long paragraphs: use bullet points, numbered lists, or short tables to highlight key facts and comparisons.
- Apply schema markup: add structured data (e.g., FAQPage, HowTo, SoftwareApplication, Organization) using plugins like Yoast SEO, or RankMath)
- Test your schema for accuracy: run your pages through a Schema Markup Validator. It will show you exactly how Google (and by extension, LLM crawlers) interpret your markup.
Strategy 2: Clarify Your Brand Across the Web
Before an LLM can cite you, it has to recognize you – who you are, what you offer, and how your brand connects to everything else it knows. And you do that through entity optimization and Knowledge Graph integration – it’s the foundation for making your brand machine-recognizable, consistent, and verifiable across the web.
Entity Optimization
Large language models build maps of entities (an “entity” is simply a distinct, identifiable thing, like a person, company, or product that search engines and AI systems can recognize across the web) of people, companies, product names, and categories.
When you say “Salesforce is a CRM platform,” systems like Google’s BERT or other large language models (LLMs) tag Salesforce as an organization, and CRM platform as the category it belongs to. That’s how they start building mental “maps” of how people, companies, and ideas connect.
This process is called Named Entity Recognition (NER), which is basically the model tagging things in your text and saying:
- “flow.io” → Organization
- “CRM software” → Product category
- “Austin” → Location
But if your brand shows up differently across the web, “flow.io” on your homepage, “Flow Tech” on LinkedIn, and “Flow Software” in a G2 listing, the model may treat them as three different entities, and that fragments your brand signal (the machine’s ability to see all mentions as one connected brand).
It’s almost like being listed under three different names in a phone book, people (and machines) can’t tell you’re the same business.
Knowledge Graph Integration
The Knowledge Graph is Google’s structured database of facts – a massive system that connects verified information about people, organizations, products, and concepts. It powers those information boxes you see on the right side of search results (with company details, founders, and related entities).
Knowledge Graph visibility adds another layer of credibility for LLMs.
Google’s Knowledge Graph and open databases like Wikidata function as fact hubs that LLMs lean on heavily.
If your company appears in these databases, you become part of their “source of truth.” But you can’t simply submit a form and get in – you have to build your way there by publishing content, keeping company info consistent across platforms, and earning citations from trusted outlets. A Wikipedia or Wikidata entry, when possible, is especially powerful because many LLMs (especially ChatGPT) tend to reference those directly.
Here’s how to optimize for entity recognition and knowledge graph integration:
1. Run NER checks on key pages.
- Use a tool like TextRazor API to see what entities Google is detecting in your content and optimize where signals are unclear.
2. Standardize your brand identity across all profiles
- Use the exact same name (e.g., “flow.io”) on your website, LinkedIn, Crunchbase, G2, Product Hunt, App Store listings, and press coverage.
- Keep the same logo, tagline, and URL format everywhere.
- If your founders or key products are listed under different names elsewhere, align them because Google and LLMs cross-reference these.
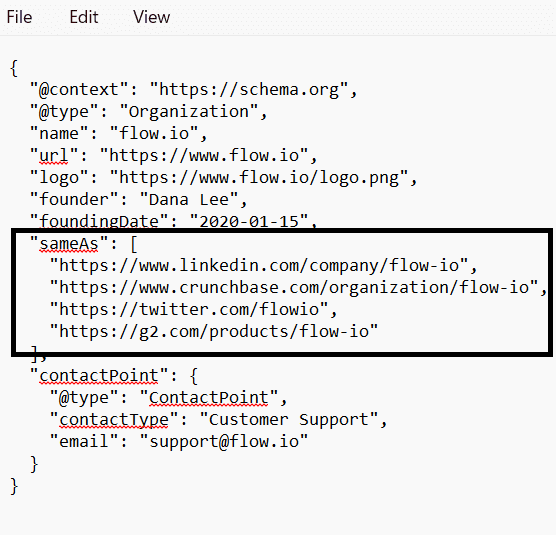
3. Add “sameAs” links everywhere possible to your schema
The sameAs property is one of the simplest but most powerful tools for entity optimization.
It explicitly tells search engines and LLMs:
“This LinkedIn page, this Crunchbase profile, this Twitter handle, they all represent the same entity.”
So include all verified, official URLs:
- LinkedIn Company Page
- Crunchbase
- G2/Capterra
- Product Hunt
- GitHub/App Store
- YouTube Channel
- Wikipedia / Wikidata (if available)
5. Build (or claim) a Wikidata entry
Google and LLMs lean heavily on Wikidata as a cross-verification source.
Here’s a quick path:
- Go to Wikidata.org.
- Click “Create a new item.”
- Add:
- Label: your brand name (“flow.io”)
- Description: what you do (“SaaS project management software”)
- Official website: link to your homepage
- Country: headquarters location
- Industry / sector: use existing Wikidata property (“Software company,” “CRM tool”)
- Founders, social links, and product relations (if applicable)
6. Earn high-authority citations
Machine verification works almost like human trust, the more credible people confirm who you are, the more you’re believed.
So aim to secure mentions in trusted sources like:
- TechCrunch, VentureBeat, or niche SaaS media outlets
- Reputable directories (Crunchbase, AngelList)
- Industry award listings or government registries
- Authoritative blogs with schema-rich articles
GEO that gets results
Not sure how GEO affects ai search visibility? We help SaaS teams apply strategies that actually get their content noticed.
Strategy 3: Use a Conversational Tone & an Answer-First Design
Writing in a conversational tone and leading with the core answer upfront helps models recognize your relevance faster and pull you more often into generated responses.
Previously, with (the non-AI-powered) Google search, users knew they had to speak the algorithm’s language. They’d type stiff, keyword-packed phrases like “blockchain definition” or “CRM software benefits.” And we, as part of standard SEO practices, optimized our content the same way, structuring pages to rank for those exact match phrases so users could click through, read multiple links, and piece together their answers.
But that behavior has changed now. Inside ChatGPT, Gemini, or Perplexity, people don’t have to “talk like Google” anymore. They can ask full, conversational questions like “What is blockchain and how does it actually work?” or “Which CRM is best for small SaaS teams?”
And the models (such as BERT) are trained for that (as discussed in the strategy above). They interpret natural-language intent, match it with semantically aligned passages from the web, to deliver a well-formed response. If your content reflects that same conversational tone, phrased the way users actually ask, you increase your odds of being cited in those answers.
Also, knowing models (and readers) prefer content where the bottom line appears first (the BLUF technique: Bottom Line Up Front), your first one or two sentences should deliver the core takeaway on their own – followed by context, examples, or supporting data.
Supporting details can flow into longer explanations or neatly formatted bullet lists and tables that LLMs can lift cleanly.

Here’s how to create answer-first, conversational content:
- Mirror natural search behavior: write the way people ask in ChatGPT or Perplexity (“how does,” “why do,” “what happens when”), not the way they typed into Google.
- Lead with the takeaway: begin each section with the clearest answer to the question before expanding on it.
- Use plain, approachable language: avoid jargon and keyword stuffing; clarity and natural flow improve LLM comprehension.
- Structure your follow-up: add supporting details in short paragraphs, lists, or tables that models can easily reuse.
Strategy 4: Leverage User-Generated Content (UGC)
Show up on platforms like Reddit, Quora, G2, and Stack Overflow, and become a part of real-time conversations happening around the problem your product solves.

These platforms are goldmines of authentic, conversational knowledge that LLMs rely on to learn how people actually talk, share advice, and describe products. A clear sign of how important that data has become is Google’s $60M/year content licensing deal (to train its AI) with Reddit (2024). That partnership is hard proof that LLMs actively draw from Reddit’s discussions to fuel their AI training and retrieval layers.
So, if your brand or product shows up naturally in those spaces, in reviews, comparisons, or forum threads, those mentions can feed into the very datasets LLMs learn and retrieve from. Over time, that strengthens your brand’s presence in AI-driven conversations.
While you can’t fully control user-generated content, you CAN influence it by showing up where those conversations happen.
Here’s how to influence UGC for AI visibility
- Identify your active communities: Find where your audience talks about your category (e.g., Stack Overflow, G2, Quora, Reddit).
- Repurpose existing content: Take insights from your blogs or guides and rework them into short, platform-friendly posts or answers that read like genuine contributions, not ads.
- Seed brand-consistent mentions: Reference your product naturally while adding value to the conversation, “we struggled with this at [brand], so we built a feature that automates X, here’s what worked”.
- Engage in ongoing discussions: Participate in relevant conversations happening on Quora, Reddit, LinkedIn, and maybe even huggingface.co because these platforms often get indexed or summarized online.
Strategy 5: Invest in Digital PR & Earn Brand Mentions
Consistent, credible mentions across high-authority publications, podcasts, and review platforms play a bigger role in LLM visibility than backlinks alone because they teach models who you are, what you do, and why you’re worth citing.
For example, a citation in TechCrunch or a respected niche blog signals legitimacy, even without a hyperlink attached.
That means if your brand narrative is consistent on your site, LinkedIn, and Crunchbase, and then shows up echoed in a third-party article, LLMs can triangulate that. The repetition across trusted contexts makes you “citable” (the model is more likely to lift your name when stitching together an answer).
This is also why we’ve shifted our off-site strategy away from chasing only do-follow links and toward securing visibility in authoritative conversations – done via Digital PR.
Here’s how to build AI-optimized digital PR
- Audit your brand mentions: Use tools like Ahrefs Mentions to track where your brand appears with or without links. Prioritize consistency in how your company and product names are represented.
- Pitch to credible outlets: Target publications and podcasts that get indexed and often referenced, TechCrunch, Forbes, Product-Led Alliance, or respected niche blogs in your vertical.
- Publish thought leadership: Contribute bylined articles, founder interviews, or case studies that feature original insights or company data (these are more “citable” by LLMs).
- Leverage data hooks: Pair your Digital PR efforts with research-backed or data-led content. For example, a mini-report or benchmark you can offer to journalists. This increases the likelihood of your insights being cited.
- Ensure consistency across sources: Align your company name, founder bios, and product descriptions across every mention. This helps LLMs associate all appearances with the same entity.
- Repurpose PR wins: Embed your best mentions into your site’s “In the News” or “Press” pages. This reinforces your authority signals for crawlers and readers alike.
Strategy 6: Experiment with llms.txt
LLMs.txt is the cousin of robots.txt. Where robots.txt tells Googlebot and other crawlers what they can or can’t index, llms.txt tells that to AI crawlers like OpenAI’s GPTBot, PerplexityBot, and Anthropic’s ClaudeBot.
It’s very new and adoption is uneven, but more and more marketers are jumping on it.
Now, you can choose whether AI bots should access all your blog posts, exclude gated content, or even point them toward specific directories you want them to crawl. Some brands are already using it to surface their clearest, most citable resources while keeping experimental or duplicate content out of the training mix.
Yoast has released its very own llms.txt generator, and more CMS tools are starting to bake it in.
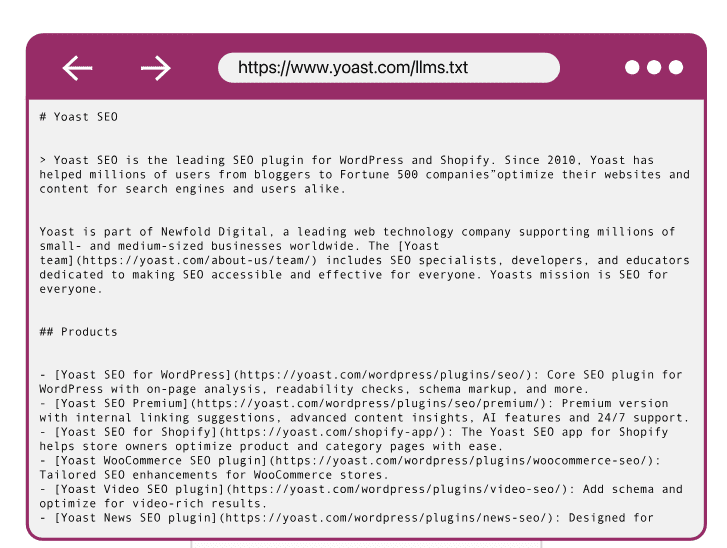
Source: Yoast
Here’s how to create and use llms.txt strategically
- Use the Yoast llms.txt Generator or similar tools (many CMSs now support this).
- List approved directories (eg, allow: /blog/) and block sensitive areas (eg, disallow: /admin/)
- Include a contact line: e.g., Contact: ai-access@yoursite.com – it signals you’re an open, cooperative data source.
- Upload it to your main directory (so it’s accessible at yourdomain.com/llms.txt)
Strategy 7: Include Clear, Fact-Checkable Statements
For all the content you create and publish, ensure clarity, and add links that LLMs can use to verify your shared information.
For example, let’s say you have written blogs to raise awareness about a problem your product solves; every stat or big claim you include should be framed as a verifiable, fact-checkable statement, backed by a credible external source. It’s one of the ways you can exhibit content-level trust signals for LLMs.
A CRM company might write, “Most sales teams waste huge amounts of time chasing unqualified leads.”
That’s true enough, but it’s too vague for an LLM to CONFIDENTALLY reuse.
A stronger, fact-anchored version would be: “According to Gartner, sales reps spend 43% of their time on lead qualification tasks (2024).” It’s a clear statement that can be independently verified, which makes it reusable inside LLM answers.
(LLMs are becoming cautious about making unsupported claims, and so they rely heavily on evidence they can verify, whether that comes from a retrieval system or well-known, reputable sources. This reliance explains why models often prefer citations from trusted names, reducing the risk of hallucination.)
Here’s how to make LLMs trust you:
- Back every factual statement with a credible source. It could be a statistic, market trend, customer behavior insight, or cost estimate. Essentially, for any number or claim that could be questioned, you have to make sure it’s verifiable.
- Keep the framing concise. Short, declarative statements (one sentence, with the source included) are more machine-friendly than burying the stat in a long paragraph.
- Prefer high-authority references. Research firms ( Gartner, Forrester), government databases, or widely trusted publishers (such as Forbes, Guardian, BBC) carry more weight than a random blog.

Strategy 8: Embed Original Data & Insights
Data-led content is most likely to win in today’s AI-driven search because it cuts through the noise of recycled opinions.
A dozen blogs can reference the same Gartner stat, but if you’re the company publishing fresh benchmarks, surveys, or usage insights, your number becomes the one that circulates through LLM/AI responses.
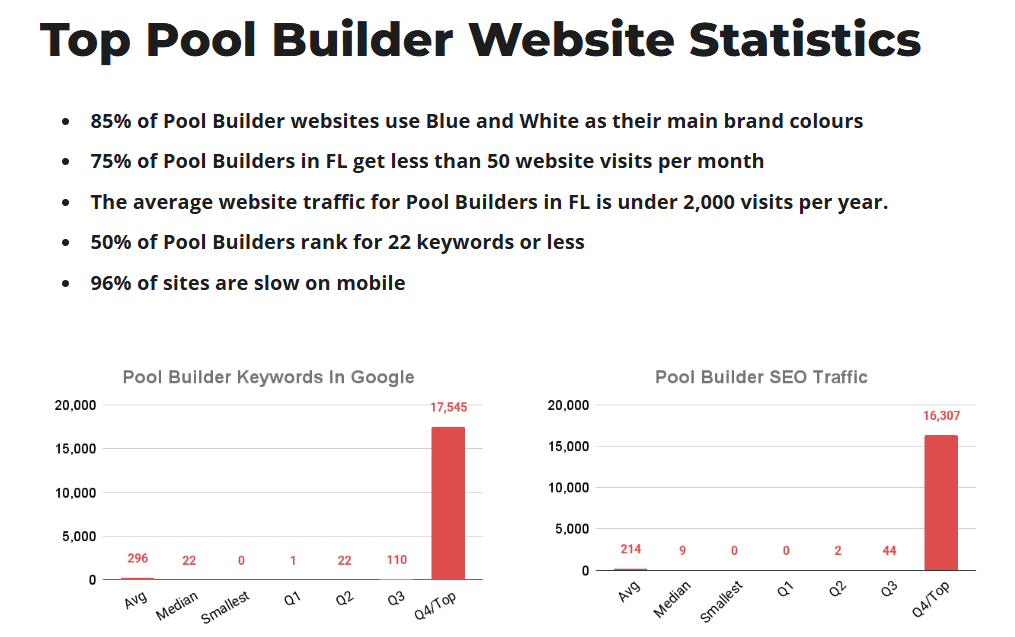
Original data from a niche analysis (pool builders in Florida), included here as an example of the kind of proprietary insights that help strengthen GEO signals.
Neil Patel makes this point directly: “Publishing unique research, case studies, or proprietary data makes your content more valuable to LLMs. These models are designed to identify and prioritize information not easily found elsewhere.” In other words, when you’re the only source with that stat, you have a natural advantage – the model has nowhere else to get it from.
For example, imagine you’re building an LLM optimization tool. If you publish a study analyzing 700 LLM responses across industries and uncover that “73% of answers prioritized content with structured tables over narrative paragraphs,” (let’s assume)that’s a finding no one else has reported. Now, when someone asks ChatGPT or Perplexity, “What factors influence whether AI cites a source?”, your study becomes one of the citable sources.
There’s also a technical reason this works. Research on generative search (arXiv, 2025) shows that LLMs prefer passages with high predictability and strong semantic alignment, and data-led content naturally delivers both:
- Predictability: Numbers are usually written in short, factual sentences (subject → verb → object), which models can parse with confidence.
- Semantic alignment: Stats often describe the exact pain points or outcomes users ask about in LLM queries, making them a natural fit for answer synthesis.
Here’s how to create and distribute original insights:
- Run small surveys with your customer base or audience and publish the results.
- Mine your customer conversations (support tickets, demo calls, reviews) and extract the 5–7 phrases that show up the most, and content around those patterns.
- Mine anonymized product usage data for patterns others can’t replicate.
- Package findings clearly with a single, declarative takeaway (“61% still do X”), ideally supported with a chart or table.
- Host it on a stable, crawlable page like a Research or Insights hub so it’s easy to reference.
So, citing others, credible sources to prove your point is one thing, but BECOMING the source LLMs and others cite is best.
Strategy 9: Maintain Freshness & Relevancy Signals
Freshness drives visibility in (LLM-powered) AI search. AirOps report shows that 95% of pages ChatGPT cites are fewer than 10 months old, and pages with a visible “last updated” schema get 1.8× more citations than those without.
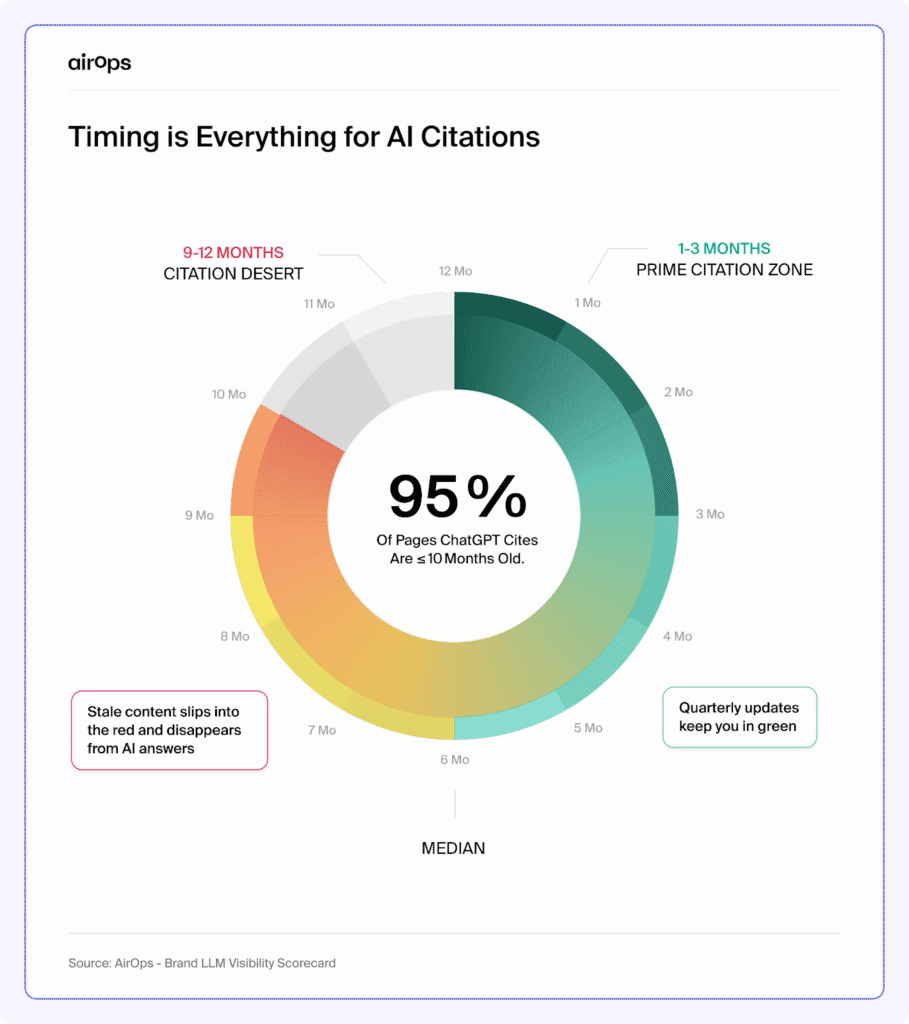
Source: AirOps
That makes recency a ranking factor of sorts in LLMs. So if your content looks stale, you’re far less likely to be pulled into an AI answer even if the information itself is still valid.
How to signal freshness and relevancy to LLMs:
- Implement “last updated” schema on high-intent pages (not just visible text). This is the machine-readable signal LLMs rely on.
- Set a quarterly refresh cycle for your most visible or strategic URLs, revisiting not just the schema but the content itself.
- Use updates as substance checks:
- Replace or re-verify stats with recent sources.
- Tie product references to current features or versions.
- Update visuals, voice, and CTAs to match your current brand and funnel strategy.

Source: AirOps
Strategy 10: Show Author Visibility & E-E-A-T
Just like Google’s ranking systems, LLMs also value signals of E-E-A-T (Expertise, Experience, Authoritativeness, and Trustworthiness) to decide if your page is credible enough to cite.
That means the “who” behind your content matters.
If an article looks like it was published by a faceless brand blog with no author, they’ll likely skip over it. BUT, if your content is tied to a visible expert, one with a name, credentials, and digital footprint, the chances of it being trusted and referenced go way up.
Here’s how to reflect strong E-E-A-T signals:
1. Show real authors: Add named bylines with role-specific bios (“Senior SEO Strategist at X,” “Data Engineer with 7 years in ML Ops”). Also include a short “Reviewed by …” credit for high-stakes or technical posts.
2. Link to verifiable profiles: Connect each author to external pages – LinkedIn, GitHub, Google Scholar, or Crunchbase so crawlers can map them into knowledge graphs.
3. Add a dedicated Author or Team page: List contributors, short bios, headshots, and links to their top pieces.
4. Strengthen site-level authority: Build a recognizable About Us, Contact, and Editorial Policy page. List real company addresses, leadership names, and press mentions (if you have earned any).
5. Keep sources transparent: Cite credible references for every claim or stat such as industry reports, government databases, or recognized publishers (e.g., Forbes, Gartner, Statista).
7. Maintain reputation hygiene: Encourage reviews on third-party sites like G2, Clutch, and Trustpilot. Positive sentiment across the web feeds into both E-E-A-T and entity confidence scores that models infer from public data.
Strategy 11: Create Deep Topic Clusters
If your SaaS site has only a single post on a subject, models (and search engines) are less likely to treat you as an authority. But if you build a cluster of interconnected content – definitions, how-tos, comparisons, case studies – all tied back to one core hub, you look like the definitive source.
And this isn’t a new concept – clustering has been around for years as an integral component of traditional SEO. But now, in this new LLM era it’s even more critical because of how query fan-out works.
When a user asks a question, ChatGPT doesn’t just search one phrasing, it spins that query into multiple variations (“affordable CRM,” “CRM for startups under $50,” “CRM with Slack integration under $50”).
To show up consistently, you need content that covers those angles. A well-built cluster gives the model multiple entry points across those fan-out queries, and when those results are fused together, your site looks stronger than a competitor with just a single “hero” page.
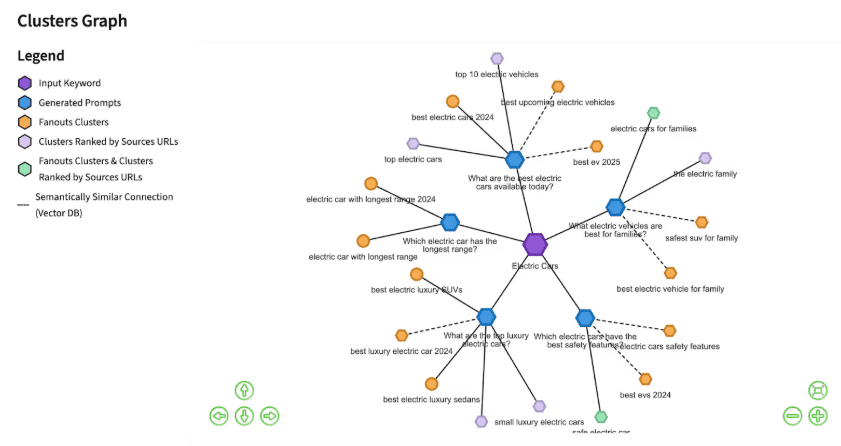
Source: SurferSEO
Also, don’t limit clusters to only keyword opportunities with measurable search volume.
Yes, those matter, but if you come across questions, angles, or subtopics that don’t register on keyword tools yet still add meaningful context to your core theme, they’re worth building into the cluster. These “low-volume but high-context” pieces may not bring you traffic from Google, but they strengthen your topical authority in the eyes of LLMs.
Here’s how to build strong topic clusters for GEO
- Pick a core theme your SaaS product or audience revolves around (e.g., predictive analytics, workflow automation, data compliance).
- Map subtopics using query fan-out tools like AlsoAsked, or Qforia to identify related question variants people ask.
- Build a pillar page that gives the full overview and link every related post back to it (and vice versa).
- Include diverse formats like tutorials, case studies, glossaries, and benchmark reports to increase surface area across retrieval types.
- Add internal linking and schema (Article, FAQPage, or HowTo) to help machines recognize the topical relationship.
- Refresh quarterly. Update data and crosslink new supporting pages as queries evolve.
-> Check our guide on how to build topic clusters that strengthen your authority for more context on this.
Strategy 12: Keep Core Content in Plain HTML
If your pricing tables, feature lists, or metadata are injected via JavaScript or locked inside images, LLMs won’t see them. To the model, it’s as if that information doesn’t exist. Because, as smart as LLMs may seem, they’re still limited in how they crawl the web. Dan Hinckley of GoFish Digital also pointed out this key gap in his LinkedIn post. He shared how Googlebot can render JavaScript and CSS, but LLM bots like ChatGPT only read the raw HTML source.
So for visibility, your critical content, the facts you want cited in answers, needs to live in plain, crawlable HTML. If a model can’t parse it directly, it can’t include you in its response.
Here’s how to make sure LLMs can read your site:
- View your raw HTML:
- Right-click any page and choose View Page Source (or press Ctrl+U/Cmd+U).
- Check whether your key content (text, pricing, features, etc.) appears there. If it doesn’t, it’s likely rendered with JavaScript and invisible to LLMs.
- Avoid JS-dependent sections for critical info:
- Keep essentials (value propositions, pricing, FAQs, reviews) in static HTML rather than sections that rely on scripts to load.
- Use text instead of images for key details:
- Don’t use images or infographics to convey facts or numbers you want models to pick up. Embed them as readable text instead.
- Inspect your metadata:
- Make sure <meta> tags (titles, descriptions, OG tags) are visible in your page source, not added later through scripts..
- Test your crawlability:
- Use tools like ChatGPT’s GPTBot Validator, Screaming Frog, or site:yourdomain.com searches to see if your content is discoverable.
- Prioritize readability and stability:
- Keep critical information on stable URLs (no heavy query strings or app fragments). LLMs rely on predictable, static structures when retrieving context.
Final Thoughts
Every day, more people are starting their discovery journeys inside LLM platforms like ChatGPT, Gemini, Claude, and Perplexity. And those journeys span every stage of the funnel.
> At the unaware stage: when users are barely aware they have a problem.
> At the aware stage: when they’re actively researching and naming it
> At the most aware stage: when they’re comparing solutions.
For your brand to be part of those conversations, your content must be bot-readable, understandable, citable, and trusted by LLMs. That means showing up with clean entities, verifiable claims, consistent signals, and enough topical depth that models can lean on you as a reliable reference.
The strategies in this guide will put you on the right track, although they don’t guarantee citations overnight – but if you stay consistent, they WILL eventually make your brand visible and usable inside the very systems that more buyers are turning to for answers.
Start with these steps:
- Audit your current content for machine-readability (entities, schema, HTML clarity).
- Prioritize a few high-intent pages to refresh with recency signals and fact-checkable claims.
- Map one or two clusters around your core problems, even if some topics don’t have measurable search volume yet.
- Start building a cadence for original data – even small surveys or usage insights can make you the only source worth citing.
GEO that gets results
Not sure how GEO affects ai search visibility? We help SaaS teams apply strategies that actually get their content noticed.

