As a content marketer, figuring out how to get LLMs to cite your brand has felt like looking into a black box.
Thanks to what’s been surfaced in dev console configs and research, we now have a clearer picture of how ChatGPT works.
Looking at the clues from publicly available sources, we know there is a multi-stage process where your brand’s content can either get cited, paraphrased, or dropped entirely while an answer is assembled.
In this guide, we’ll break down those 7 stages, so you can see exactly where and how your brand has a chance to surface.
TL:DR;
- Pretraining data: The background information that exists in the LLM from sites like Wikipedia, Crunchbase, or major news outlets.
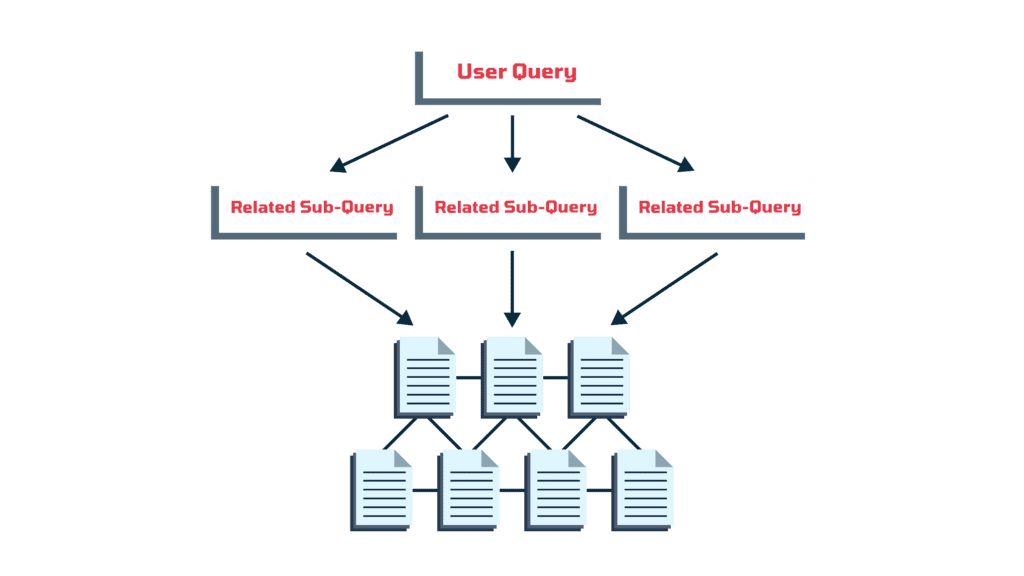
- Stage 1: Query fan-out: ChatGPT rewrites a single prompt into many variations.
- Stage 2: Retrieval: The LLM pulls candidates from the web and connected sources, mixing keyword matches with semantic embeddings.
- Stage 3: Fusion (RRF): Results from multiple queries are merged.
- Stage 4: Reranking: A neural model reshuffles results based on quality signals — structure, depth, clarity, authority.
- Stage 5: Freshness scoring: Pages updated recently get weighted higher.
- Stage 6: Safety filtering: ChatGPT flags suspicious code, obfuscated scripts, or risky markup.
- Stage 7:Answer assembly: ChatGPT compiles sources to give an answer.
How ChatGPT Processes and Ranks Your Content (in 7 Stages)
Pretraining data: ChatGPT’s Built-in knowledge
Part of ChatGPT’s database is frozen in time. It was trained on a big snapshot of the internet that includes sources like Wikipedia, Wikidata, Crunchbase, G2 reviews, and major news outlets.
If your brand was mentioned across the web when this snapshot was taken, you start with a bit of an advantage. The system has “seen” you before, so you’re not a stranger when someone asks about your category.
But if you weren’t, you may not surface quite as easily as companies that were. While you may be at a slight disadvantage, the story isn’t over. Brands will have to focus on meeting ChatGTP’s content preferences to continue being cited, no matter what their web presence looked like when the LLM was being trained initially.
Stage 1: Interpreting, Rewriting, and Expanding the Query
ChatGPT starts every answer with an intent check. The system analyzes what kind of answer fits best:a definition, a comparison, a step-by-step guide, or something else? Once intent is set, the query expands outward, and the system generates a bundle of related questions, which is a process known as query fan-out.
A prompt like “best CRM for startups under $70” often branches into variations such as “affordable CRM software,” “CRM with Slack integration under $70,” or “small business CRM comparison.” ChatGPT does this so it can cover the different ways people might phrase the same need.
For SaaS brands, this is where breadth pays off. When you have a site built around clusters, with a hub page for the main topic and supporting pages that go into different angles, your brand is better positioned to be retrieved across multiple fan-out variations. You’re essentially giving the system many different entry points to bring your brand into the conversation.
Stage 2: Retrieval (web + connected sources)
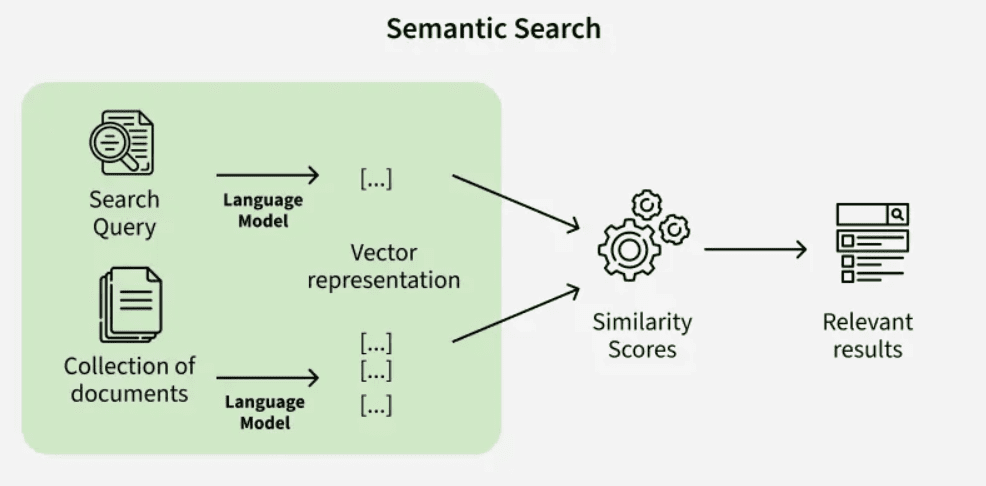
Once ChatGPT has spun out a bundle of related queries, it goes looking for answers. This retrieval stage pulls in material from the public web, and, if a user has connected services like Google Drive or Notion, it can also reach into those private sources.
The system doesn’t rely on one type of matching. It mixes straightforward keyword lookups with vector embeddings (different types of data – text, audio – expressed in numerical form), which allow it to spot meaning even if the wording isn’t exact (called the semantic search).
Filters are applied by source and file type to make sure the right kinds of documents (in-depth, unbiased) are being considered.
Source: GeeksforGeeks
For you, this is the first real point of influence. If critical information about your product is hidden behind JavaScript, buried in images, or spread across unstable URLs, the system may not even grab it in the first place.
Stage 3: Fusion across multiple searches
By this point, ChatGPT has a pile of results from all of its fan-out queries. The next step is to merge them into one unified list. The method it uses to do that is called Reciprocal Rank Fusion (RRF). This process rewards pages showing up consistently across query variations rather than just for one.
Every time a page appears in a search variation, it gets a score. Here’s the formula ChatGPT uses to score a page for every fan-out query:
RRF score = 1 / (60 + rank position)
That number seems small at first, but the trick is in how it adds up across all the different queries.
Here’s a simple example:
- If your page ranks #1 for one query, you get: 1 / (60+1) = 0.0164.
- If you rank #5 for ten related queries, each one scores 1 / (60+5) = 0.0154. Added up across ten queries, that’s 0.154.
That means if your site is ranking #5 for ten related searches, it will carry more weight than a site ranking #1 for just one.
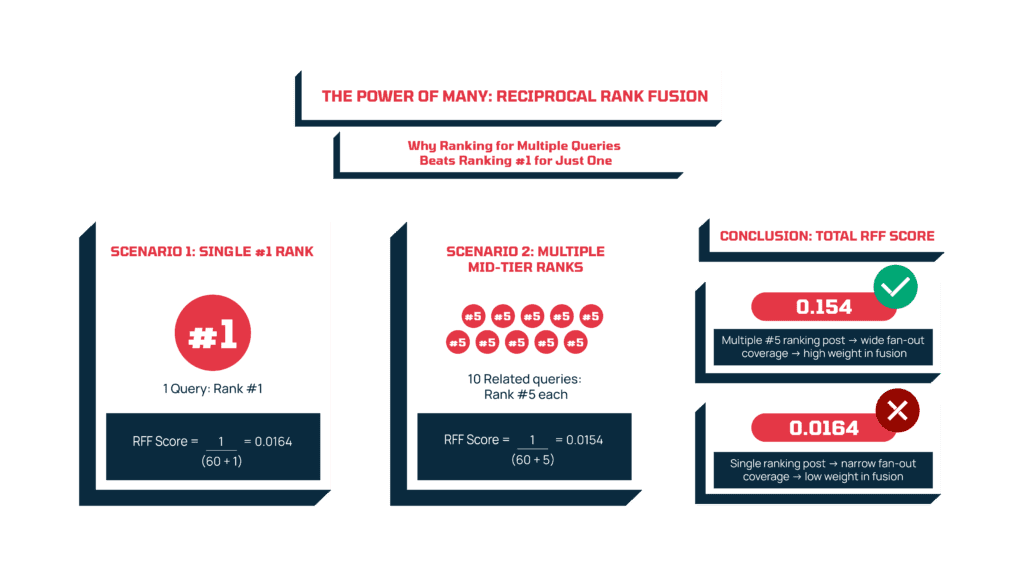
For SaaS brands, this reinforces the importance of topical depth. When you cover all the natural variations and use cases around a core topic, you’re more likely to rank across many of ChatGPT’s fan-out queries, and those repeated mid-tier rankings add up to more influence than a single #1 result.
Understand chatgpt rankings
ChatGPT decides what gets attention, and it’s not always obvious how. Book a quick session with us to help you understand the process so your content gets seen.
Stage 4: Reranking & quality weighting
After fusion, ChatGPT runs the remaining candidates through a second pass using a neural reranker (listed in the config as ret-rr-skysight-v3).

This is a screenshot from ChatGPT’s internal configuration settings showing the active reranking model (ret-rr-skysight-v3). This parameter confirms that ChatGPT uses a neural reranker to reorder retrieved results based on relevance, quality, and authority before assembling its final answer.
Source: Metehan.ai
This model reshuffles results based on signals of quality to pull from relevant and trustworthy content.
So what counts as “quality” here? At this stage, ChatGPT is looking for pages where:
- The main answer is stated clearly, not buried halfway down the page
- The explanation stays tightly on-topic instead of drifting into side stories
- The details are specific enough to be useful (numbers, ranges, concrete conditions, examples)
- The reasoning is simple enough to follow without guesswork
- The information is grouped in a way that makes it obvious what each part is about
So content teams should:
- Start key sections with a one-sentence, plain-language answer before you unpack the details.
- Break topics into clear H2/H3s and keep each section focused on one sub-question.
- Use tables, bullets, lists, and FAQs when you’re listing options, steps, or comparisons so the model can lift them cleanly.
- Where it makes sense, add ranges, examples, “if/then” conditions, or simple steps instead of staying vague.
Stage 5: Freshness Checks
ChatGPT gives extra weight to information that looks current. In its configuration, this is called a freshness scoring profile, and it’s always on. That means even the most detailed guide can lose ground if it hasn’t been updated in a while.
A visible “last updated” date, refreshed sitemaps, and real content edits help signal to the system that your page is still relevant.
Stage 6: Safety & policy filtering
At this stage, content is scanned for things that might look like prompt injection attempts, unsafe strings, or policy violations. Pages that trigger those alarms don’t make it through to the reranker, no matter how strong the content is.
You might not be doing any of that intentionally, but if you leave a page cluttered with obfuscated scripts, hidden code blocks, or markup that looks suspicious, the system may treat it as risky. Legitimate code samples can raise flags if they aren’t scoped and presented cleanly.
So regularly audit your pages for stray code. Strip out leftover divs, broken embeds, half-rendered widgets, and old plugin markup. Make sure every code snippet is intentional and clearly labeled.
Stage 7: Answer assembly (mention vs. citation)
Finally, how ChatGPT shows your brand in an answer depends on the type of query being asked.
For decision-level queries: questions where the user is weighing options, like “What’s the best CRM for startups under $50?” ChatGPT usually won’t link directly to a product’s pricing page. Instead, it cites the sources it relied on to decide which tools to recommend, such as review sites or comparison articles. This helps the answer look balanced and verifiable, even if it means the brand itself isn’t the clickable link.
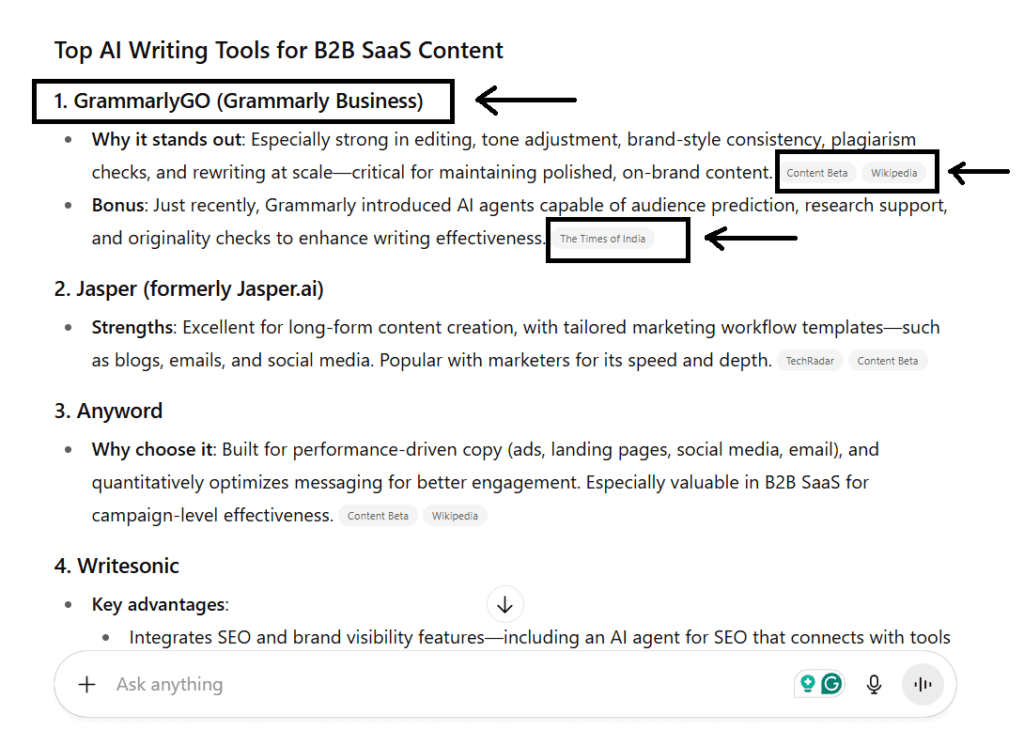
Screenshot: An example of how ChatGPT cites the third-party sources it relied on when recommending a tool
For more exploratory or informational queries, the system often just names products in passing. Mentions like “Tools such as X, Y, and Z are popular choices” are common, and they still carry weight because readers treat them as neutral suggestions.
Either way, to show up in the final text, your brand needs to be present in the third-party sources ChatGPT trusts and create content that can be paraphrased naturally into an answer.
Final Thoughts
The mechanics behind ChatGPT’s mentions follow a structured pipeline (query expansion, retrieval, fusion, reranking, freshness, and safety filters) that decides what gets surfaced and what gets left behind.
For you as a founder or marketing lead, the main takeaway is that there are multiple checkpoints where your content can be eliminated.
To avoid this, you need to align with the system’s priorities:
- Be consistently present across fan-out queries
- Structure your pages so they’re easy to parse
- Keep them visibly fresh, and show up in trusted third-party sources.
Surviving all seven stages is what gives your brand the best chance of being used in ChatGPT’s final answer.
Understand chatgpt rankings
ChatGPT decides what gets attention, and it’s not always obvious how. Book a quick session with us to help you understand the process so your content gets seen.
FAQs
Can I make my brand show up in ChatGPT’s pretraining data now?
No, the pretraining layer is frozen at the cutoff. If your brand wasn’t in Wikipedia, Crunchbase, G2, or similar sources before then, you can’t retroactively add yourself. Your opportunity is in the live retrieval stages, where new and updated content gets pulled in.
Will ChatGPT link to my website, or just mention it?
ChatGPT often mentions brands in plain text. In decision-level answers, ChatGPT tends to cite external sources (like review sites or comparison articles) instead of direct product links. Mentions still matter as they help with brand reputation and visibility even without a hyperlink.
Why doesn’t ChatGPT mention my brand even though I rank on Google?
ChatGPT doesn’t use Google rankings directly. It uses its own retrieval + reranking pipeline. Even if your page ranks high in Google, it might fail at one of ChatGPT’s stages, e.g., failing freshness scoring or being filtered out by safety/noise filters. Showing up in ChatGPT requires catering to those extra checkpoints, not just SEO.
How do I measure mentions in ChatGPT?
Use AI visibility tools like Peec. They automate prompt testing for ChatGPT (and whatever other LLM you want), log when and where, and how your brand is mentioned, and track competitor presence. Pair that with Search Console impressions for branded + category terms: if both are trending up together, it’s a strong signal your optimization is working.
